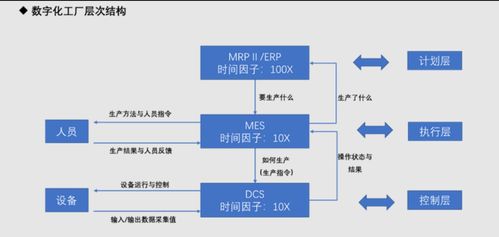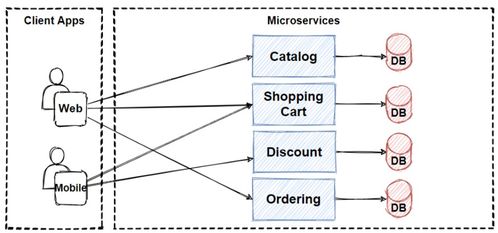
在构建高可靠性的应用知识图谱过程中,数据处理服务作为底层支撑的核心环节,其架构的演进直接决定了知识图谱的质量、实时性与稳定性。从早期的手工构建到如今的智能化、自动化处理,数据处理服务的演进之路体现了技术迭代与业务需求的双重驱动。
一、 初始阶段:人工主导的离线批处理
在知识图谱应用的萌芽期,数据处理服务通常以离线批处理为主。架构相对简单,核心是ETL(抽取、转换、加载)流程。数据源有限,多为结构化数据(如数据库表)。处理逻辑由开发人员手动编写规则和脚本实现,知识抽取和融合的准确性严重依赖专家经验。服务可靠性通过基础的故障重试和日志记录来保障。此阶段架构的痛点明显:周期长、无法响应变化、扩展性差,难以支撑高可靠、高时效的应用需求。
二、 成长阶段:自动化流水线与初步实时化
随着数据量增长和业务对时效性要求提高,数据处理服务进入以自动化流水线为特征的阶段。架构上开始引入调度框架(如Airflow、Oozie)来编排复杂的ETL任务链,实现了任务的自动化管理与监控。数据处理开始支持半结构化和非结构化数据(如文本、日志)。知识抽取环节引入了基础的机器学习模型(如NER命名实体识别),减少了人工干预。服务可靠性通过任务依赖管理、失败告警和资源隔离得到提升。该架构仍以“T+1”的批处理为主,实时性不足,知识更新延迟较大。
三、 成熟阶段:流批一体与智能化处理
为满足高可靠性应用对实时知识获取和更新的迫切需求,数据处理服务演进至流批一体的融合架构。这是架构演进的关键一跃。
- Lambda/Kappa架构应用:Lambda架构并行维护批处理层和速度层(流处理层),分别保证数据的全局准确性和低延迟。随后更简洁的Kappa架构兴起,主张全部通过流处理实现,并通过重播机制解决历史数据问题。这大幅提升了知识图谱的实时性。
- 智能化处理深化:深度学习和自然语言处理技术被深度集成。利用BERT、GPT等预训练模型进行更精准的实体链接、关系抽取和属性填充。知识融合环节引入图表示学习和实体对齐算法,自动化水平与准确性显著提高。
- 可靠性设计体系化:服务架构全面拥抱云原生和微服务理念。数据处理各环节(采集、清洗、抽取、融合、存储)被拆分为独立可扩展的服务。通过容器化部署、服务网格、完善的监控告警(Metrics, Logs, Traces)以及自动化弹性伸缩,构建了高可用的服务集群。数据质量监控和血缘追踪成为标配,确保处理过程的可观测性与可回溯性。
四、 前沿与未来:主动学习与云原生Serverless化
当前,数据处理服务正朝着更智能、更弹性、更透明的方向演进。
- 主动学习与持续学习:系统能够自动识别处理过程中的不确定样本或新增数据模式,主动发起人工标注请求或模型迭代训练,形成“数据-模型-知识”的闭环优化,使知识图谱具备持续进化的能力。
- 云原生与Serverless化:数据处理任务进一步抽象,依托FaaS(函数即服务)和Serverless计算平台。开发者只需关注处理逻辑,平台负责极致的弹性伸缩、资源调度和故障恢复,极大提升了资源利用率和运维效率,为高可靠性提供了底层保障。
- 数据治理与可信AI:在架构中深度集成数据安全和隐私计算技术(如联邦学习、差分隐私),确保知识处理过程合规。增强知识推理过程的可解释性,构建可信的知识图谱。
高可靠性应用知识图谱的数据处理服务架构演进,是一条从“人工离线”到“智能实时”,从“单体僵化”到“云原生弹性”,从“单纯处理”到“治理与可信”的持续进化之路。每一次演进都是为了更好地平衡数据的规模、速度、质量与价值,最终为上层智能应用提供坚实、可靠、鲜活的知识基石。未来的架构将继续以业务需求为牵引,深度融合AI与云原生技术,向自治化、智能化的数据处理服务迈进。